
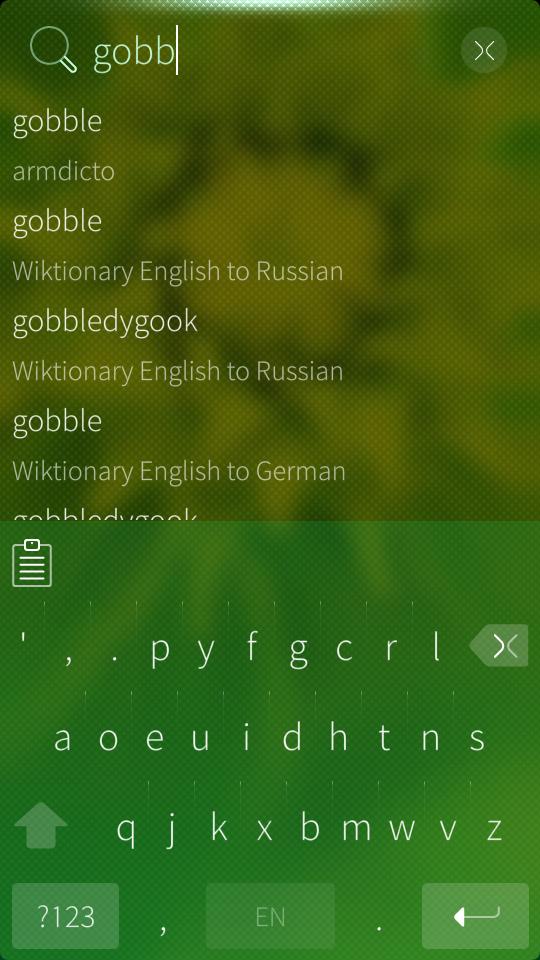
նոյնիսկ լինգուօյի բառարանում էր։
#օտարատեածութիւն #խաչիկ #բառարան #էկրանահան #ռուսերէն
կարելի ա մտածել որ հաւակերը՝ հաւ ուտողն ա։ բայց պարզւում ա՝ հաւերի կերն ա։

մարդակերն էլ հետեւաբար կարող ա լինել մարդու կերը։ գնամ խանութ մարդակեր բերեմ։
#հաւակեր #հայերէն #բառարան #էկրանահան


հմմ, համ իմ, համ @tigran@xn–y9a6bah4ck.xn–y9a3aq ֊ի պդֆ֊ից կոնուերտած նիշքերում »զեղջ» ա գրուած։
#էկրանահան #բառարան
արցախի առցանց գրադարանը գոյութիւն ունի, ու հրապարակել ա ղարաբաղի բարբառի բառարան։
@tigran@xn–y9a6bah4ck.xn–y9a3aq
#բառարան #արցախ #բարբառ #հայերէն
stardict֊ը հանել են gentoo֊ից։
բայց մնացել ա հրամանային տողի sdcv֊ն։
ստարդիկտը սակայն սիրում էի մի բանի համար՝ որ տեքստ կարդալիս բառը նշում էի, ու տակից գրում էր թարգմանութիւնը։
աչքիս պէտք ա գրել տէնց մի բան։ կամ ինչ֊որ ձեւ plumbing սարքել, միացնել։
goldendict֊ը qt ա, չեմ սիրում։
կայ gnome-dictionary որը համ բարեբախտաբար իմ դէպքում ոչ մի կախուածութիւն չունէր, ու խօսում ա քո լոկալ կամ հեռակայ dictd սպասարկչի հետ։ բայց dictd֊ն չի սպասարկում stardict֊ի ֆորմատի ֆայլերը։ իրա ֆայլերը այլ են։ գտայ dictconv֊ը, որը անում ա։ բայց sourceforg֊ի վերսիան բիլդ չի լինում նոր քոմփայլերներով։ փաթչ արի, աշխատեցրի։
dictd֊ն չկարողացայ կարգաւորել որ իմ ասած տեղից գտնի բառարան, բայց իրա ուզած /usr/share/dict֊ի միջից գտաւ իմ կոնուերտած բառարանները։
հիմա էլ gnome-dictionary֊ին չեմ կարողանում ասել որ լոկալ սերուերից օգտուի՝ ինքը էդ կարգաւորումը պահում ա նոյնիսկ ոչ օգտատիրոջ պանակում, այլ /usr/share֊ում։ ու եթէ նոյնիսկ էնտեղ ձեռքով փոխում եմ՝ չի ուզում աշխատել, բողոքում ա կոնֆիգի վրայ։
պէտք ա հասկանալ դեռ, բայց արդէն յոգնել եմ, մի այլ անգամ կը զբաղուեմ։
ու տէնց։
#բառարան
այսօր ուզում էի մէջբերել ու հասկացայ որ էստեղ չեմ վերբեռնել որեւէ բան mstardict֊ի մասին։
ահա՝




#մաեմօ #բառարան #յաւելուած

նելլի բարաթեանի բառարան։
#բարաթեան #բառարան #նկար
վերջերս հետաքրքրեց երեք բառի ծագումնաբանութիւն՝
ղալաթ, մետրօ, ու սլոբոտկա։
նախ մտածեցի՝ տեսնես, ղալաթը պարսկերէ՞ն ա թէ՞ թուրքերէն։ փնտրեցի «galat»֊ը։

գտաւ ինդոնեզիերէն։
նշանակում ա՝ «error» — սխալ։
փորձեցի «ghalat»՝

ապա գտաւ «հինդի» լեզուի բառ։
հմմմ, իսկ ես մտածում էի լրիւ այլ բան։
ապա փնտրեցի նայիրիի բառարաններում՝

ասում ա՝ արաբերէն։
ու հետաքրքիր ա, մալխասեանցի բառարանը 1944 թուի, իսկապէ՞ս դասական ուղղագրութեամբ ա։
նաեւ մտածում էի՝ տեսնես, ինչո՞ւ մետրօ։
մետրօպոլիտէն՝ ենթադրեցի որ պօլիս բառից կը լինի երկրորդ մասը։ յիշեցի, որ ռուսները, կայսրութեան կենտրոնին յղելիս ասում են՝ «մետրոպոլիա»։
պարզւում ա, «մետրօ»֊ն՝ յունարէն «մայր» ա, մայր քաղաք ա, մայրաքաղաք։
կամ դրա հետ կապ ունեցողները։
ստեփանաւանում կայ «սլոբոդկա» ռեստորան, գիւմրիում՝ նման անունով թաղամաս։
պարզւում ա, «սլոբոդա»֊ն «սուոբոդա» բառի հետ կապ ունի՝ ազատութեան մասին ա։
«սլոբոդա»֊ները հատուկ կարգավիճակով թաղամասեր, գիւղեր, տարածքներ էին, ուր բնակիչները ստանում էին որոշակի արտօնութիւններ, կամ ազատուիթիւններ՝ օրինակ հարկերից, կամ ֆեոդալներից։
յաճախ քաղաքներում դրանք պետական աշխատողներ էին։ բայց կային, նման, ազատ կարգավիճակով գերմանական բնակավայրեր, զի ռուսական կայսրութեանը պէտք էին մարդիկ, եւ գերմանացիներին տրամադրում էին արտօնեալ պայմաններ, միայն թէ գային, ապրէին։
ու տէնց։
#ղալաթ #մետրօ #սլոբոդկա #սլոբոտկա #սլաբոտկա #քաղաք #ծագումնաբանութիւն #բառարան #էկրանահան #պատմութիւն
զաթարի մատուցող էրեխէքին ոնց որ շապիկ են բաժանել, յետոյ իրար մէջ ասացին՝ «ջիւերը գերանգ»։ արեւմտահայերէն յայտնի արտայայտութիւն ա։
նայիրի֊ով ստուգեցի, կայ «ճիւ» բառը՝
1. ՃԻՒ ճուի, ճուեր
գոյական
1. Թեւ՝ թռչունների և մարդկանց։
‣ Հաւի ճիւը կտրեց, կերաւ։
‣ Ճիւէդ բռնած քեզ դուրս են հանում։
2. Ոտք, սրունք՝ թռչունների և մարդկանց։
‣ Ոմանց թեւերը ջարդեցին, ոմանց ճուերը։
‣ «Լուերն ելան ճըւերս ի վեր» (ժողովրդական երգ)։
3. Ընդհանրապէս՝ մարմնի որևէ անդամ։
4. Օղի՝ ապարանջանի կեռ ունկ, որ անցնում է ականջի ծակով կամ որով կողպվում է։
‣ Օղիս ճիւը կոտրվել է։
‣ Ապարանջանի ճիւը դուրս չի գալիս, չի բացվում։
այնպէս որ, «ճիւերը կերանք», երեւի պատանիների արտայայտութիւն ա, ուր ճիւը՝ «ընդհանրապէս, մարմնի որեւէ անդամ» իմաստով ա։
#հայերէն #արեւմտահայերէն #լեզու #ճիւերը_կերանք #բառարան #բառեր #բառ

#էկրանահան #բառարան #ստարդիկտ #տոկիպոնա #տոկի-պոնա #տպ

#ծմակ #հայկազեան #բառարան #էկրանահան
#հայերէն #տոկի-պոնա #բառարան #տոկիպոնա
 @{ քամի ; o_o@spyurk.am} 4/15/2020, 11:00:16 PM
@{ քամի ; o_o@spyurk.am} 4/15/2020, 11:00:16 PM
լուծեցի առաջին անհրաժեշտութեան խնդիրներիցս եւս մեկը՝ տօկի պօնա֊հայերէն բառարան
#տօկիպօնա #բառարան #թարգմանութիւն
http://www.goethe-verlag.com/book2/_VOCAB/HY/HYSR/22.HTM #բառարան

փաստօրէն կուրտկա֊ն բառարանային բառ ա։ #կուրտկա #բաճկոն #էկրանահան #բառարան #հայերէն
Այ֊այստեղ կայ Բարաթեանի բառարանի pdf նիշք։
Իր հետ, սակայն շատ բան չես անի՝ armscii-8 կոդաւորում, տպելու համար նախատեսուած ֆորմատ։
Իսկ մեզ (յուսով եմ ոչ միայն ինձ) կրկին պէտք է էլեկտրոնային ազատ ֆորմատի բառարան, չէ՞։ Ահա, ստացայ։
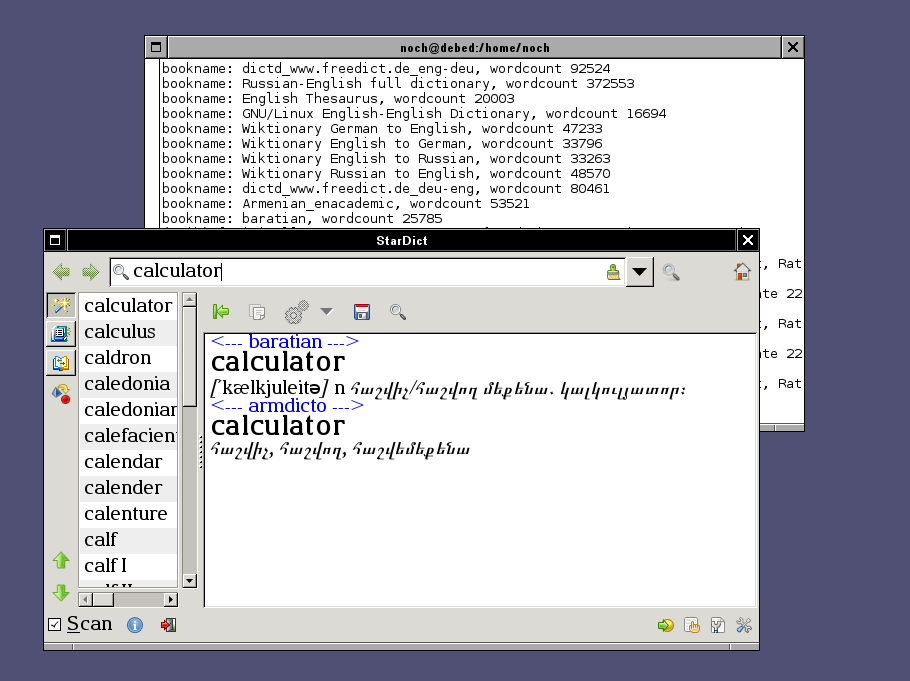
Ներբեռնել ստարդիկտ ֆորմատով այստեղ։
ելատեքստը, որի միջոցով ստացայ տաբ֊երով բաժանուած նիշք՝ այստեղ։
եւ ինքը՝ տաբ֊երով բաժանուած նիշքը որպէս աղբիւր՝ այստեղ։
վայելէք։ (:
հ․ գ․
մի քիչ պատմեմ գործընթացի մասին։
նախ, ես փորձում էի կիրառել poppler փաթեթի pdftotext֊ը, փիդիէֆ նիշքից տեքստ ստանալու համար։
սակայն կար հիմնական երկու խնդիր․
առաջին խնդիրը՝ կոդաւորումների հետ խառնաշփոթն էր։ լռելեան pdftotext֊ը ենթադրում է որ -enc UTF-8 արգումենտը։ ի դէպ, առաջ դա -enc Latin1 էր։ Ինչեւէ, այդ դէպքում, տրանսկրիպցիան ճիշտ էր երեւում, իսկ բառարանի հայերէն armscii-8 տեքստը դառնում էր մուլտիբայթ անհասկանալի մի բան, ինչ֊որ փչացած կոդաւորում։
եթէ կիրառում էի -enc Latin1, ապա pdftotext֊ը միայն Latin1 սեգմենտի տառերն էր վերցնում գրքից, իսկ Լատին մէկի ոչ բոլոր նիշերն են ընկած armscii-8֊ի տիրոյթում, եւ տառերի մի մասը կորում էին։
լուծեցի այսպէս՝ երկու նիշք էի ստանում, utf-8 եւ ucs-2 արգումենտներով։ առաջինից վերցնում էի տրանսկրիպցիաները, երկրորդի մէջ ամէն armscii-8 նիշը դառնում էր երկու բայթ, որի առաջին բայթը 00 էր, իսկ երկրորդը՝ նոյն այդ armscii-8 նիշը, եւ այսպէս 00֊ն արհամարհելով լինում էր աշխատել։
երկրորդ խնդիրը՝ այդ տեքստը չափազանց ոչ ռեգուլյար տեսք ունէր, ու կոդի մէջ լիքը բացառութիւններ էի աւելացնում։
երբեմն տողերն էին խառնուած, իսկ մի անգամ, ասենք bethink բառի տրանսկրիպցիան, թռել֊գնացել էր էջի վերջը։
Եւ դա արդէն լուծւում էր միմիայն ահաւոր շատ բացառութիւններ եւ ֆիքսումներ անելով տեքստի մէջ։
Բնական է, ես սկսեցի ատել այդ կոդը։
Փորձեցի լիքը այլ գործիքներ փիդիէֆ֊ից տեքստ ստանալու համար, ներառեալ podofo, ghostscript, եւ abiword (որը պարզւում է կարելի է հրամանային տողից աշխատեցնել, ասել որ կոնուերտի, բայց դրա ելքը նոյնն էր, ինչ pdftotext֊ինը, հաւանաբար այն պոպլերից էր օգտւում)։
մնացածի ելքն էլ ինձ չէր բաւականացնում՝ էլի խառն էր եւ անորակ։
Պարզւում է, սիրելիներս, մենք չունենք լաւ աշխատող ազատ գործիք, որ կարողանում է փիդիէֆ֊ներից տեքստ հանել։ atril֊ում էլ երբ մի բառ նշում ես, ուրիշ տեղ է նշւում։ Այդ իմ նիշքի դէպքում, բնականաբար։ (:
Ստիպուած եղայ փորձել սեփականատիրական acroread։ Տեսնեմ՝ այն ունի հրամանային տողի արգումենտներ (acroread -help), բայց, աւաղ, կարողանում է այդպէս միայն postscript նիշք տալ, եւ ոչ թէ տեքստ։ Իր տուած postscript֊ի մէջ ինձ անհրաժեշտ բան չգտայ, շատ բարդ եւ խառը ելք էր։ Այդ ծրագիրը նաեւ կարող է տեքստ տալ, բայց ոչ հրամանային տողից, այլ file – save as text ընտրելով, ու այդ տեքստը բաւական լաւ կազմ ունի։
Այդ տեքստն էլ օգտագործեցի, կոդն էլ սիրունացաւ։ Դա այն չէ, ինչ ես ուզում էի, քանի որ հիմա ես գիտհաբի շտեմարանում ունեմ որպէս աղբիւր այդ ակրորեադի տուած տեքստը, իսկ ուզում էի քաշել կայքից բարաթեանի բառարանի փիդիէֆ֊ը՝ որ փիդիէֆ֊ից մինչեւ ելքային ստարդիկտ նիշքեր ամէնը կատարուի աւտոմատացուած։
Ակրոբատի ելքն էլ էր պարունակում փչացած կոդաւորում, ինչպէս եւ պոպլերինը, երբ UTF-8 կոդաւորումն է ընտրած։
Հայերէն տեքստը պարունակում էր տարօրինակ շատ c2 եւ c3 նիշեր։
Ուշադիր նայեցի, c2֊ին յաջորդող թիւը՝ դա եղած տառի armsci կոդն է։ իսկ c3֊ից յետոյ գտնուողը պարզ չի ինչպէս է փչացել։ յետոյ նկատեցի, որ overflow է եղել իր կոնուերտացիայի ժամանակ, որը ես կարող եմ կոմպենսացնել, c3֊ին յաջորդող նիշին գումարելով 64։
Ահա, այդ պատճառով իմ կոնուերտեր մոդուլը կատարելագործուեց, ու հիմա ունի corrupted ArmSCII-8 to UTF-8 կոնուերտող ֆունկցիա։
Մնացած մանրուքները լաւ չեմ յիշում։ Կուզէի գտնել լաւ կոնուերտեր ու գործընթացը դարձնել լրիւ աւտոմատ։
այսօր Մարատի հետ էի հանդիպել, խօսեցինք մասնաւորապէս քինդլի համար հայերէն բառարանների մասին, ու մտածեցի, իսկ ինչպէ՞ս կոնուերտել բառարանային տաբ նիշքը քինդլի համար մոբի նիշքի։ կարդացի ու ահա թէ ինչ ստացուեց։
վերցնում ենք ասենք armdicto.tab նիշքը այստեղից՝ http://norayr.am/armdicto/armdicto.zip
մեզ պէտք է
tab2opf.py փայթըն սկրիպտը(https://github.com/apeyser/tab2opf)։
mobigen ծրագիրը(http://www.mobipocket.com/soft/prcgen/mobigen.zip)։
լցնում ենք բոլորը նոյն պանակի մէջ․
փայթըն սկրիպտը թեստաւորել եմ փայթըն երեքով՝
python tab2opf.py armdicto.tab
—————————–
—————————————————
խմբագրում ենք ստացուած armdicto.opf֊ը։
այսպիսի տող կայ, երեւի պէտք է պահել, քանի որ լեզուն անգլերէնն է՝
—
—
իսկ սա փոխել այսպէս՝
—
—
հիմա պատրաստում ենք մոբի նիշքը
——————————————-
—————————————–
զգուշացումներն այն պատճառով են, որ պէտք էր cover նիշք աւելացնել։
ահա ստացանք մոբի նիշքը՝
———————————
————————————
լցրի քինդլի մէջ, documents պանակի մէջ ստեղծեծի եւս մի պանակ, ու այնտեղ, յետոյ անջատեցի քինդլը համակարգչից, սեղմեցի
սենդուիչի կոճակը գլխաւոր ցանկի աջից
Einstellungen (հաւանաբար Settings, ինձ մօտ գերմաներէն է միջերեսը)
Geräteoptionen (սարքի յատկութիւնները)
Sprache und Wörterbücher (լեզուն ու բառարանը)
Wörterbücher (բառարանը)
այստեղ կայ ցանկ, ու կարելի է ընտրել նոր ստացուած armdicto֊ի նիշքը։
ու ապա թեստ՝
}}
իսկ ահա, որ ինքներդ չգեներացնէք, պատրաստի ․մոբի նիշք՝ dictionaries.arnet.am/armdicto.mobi
հ․ գ․ տեսականօրէն, կայ մոբիգեն ծրագրի լինուքս վարկած (https://disposed.de/pub/mobigen_linux.tar.gz) բայց այն իմ մօտ չաշխատեց, պահանջում է հին լիբսի, հիմնականում այդ պատճառով։ սակայն ուայնով ուին֊ի վարկածը բաւական էր։
քինդլի համար ստացայ անգլերէն֊հայերէն բառարան՝ http://dictionaries.arnet.am/armdicto.mobi
այսպէս՝ http://norayr.am/weblog/2016/04/24/15532/
մինչ։ #բառարան #անգլերէն #հայերէն #անկապ
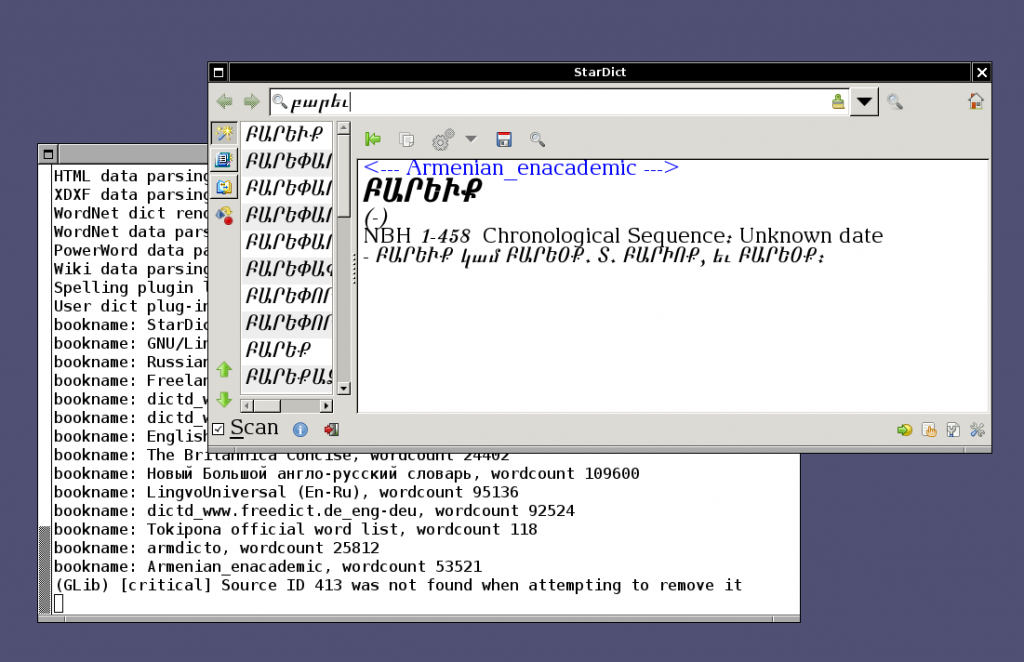
Կապուել են թուանշային գրադարանից, ասում են, իրենք են ի սկզբանէ թուայնացրել այդ բառարանը։ Կոչւում է Նոր Հայկազեան Բառարան։ Տասնիններորդ դարի բառարան է։ Ես էլ չիմանալով այն անուանում էի էնակադեմիկի բառարան։ Հետաքրքիր է իմանալ ինչպէս այն յայտնուեց էնակադեմիկ կայքում։ Լաւ է որ պարզուեց։
————————————
նախորդ գրառման հետքերով, բացառուած չէ, որ գուգլն էլ է օգտուել իմ կոտրած եւ հասանելի դարձրած «տրոյ»֊ի կազմած «արմդիկտօ» բառարանից՝
Փնտրում ենք «Սիդուդիկտ»֊ում բառը՝
Իսկ ահա գուգլ թարգմանչի արդիւնքները(սեյլֆիշի «թաօ տրանսլատոր» ծրագրով)՝
եւ գուգլի կայքի միջերեսով՝
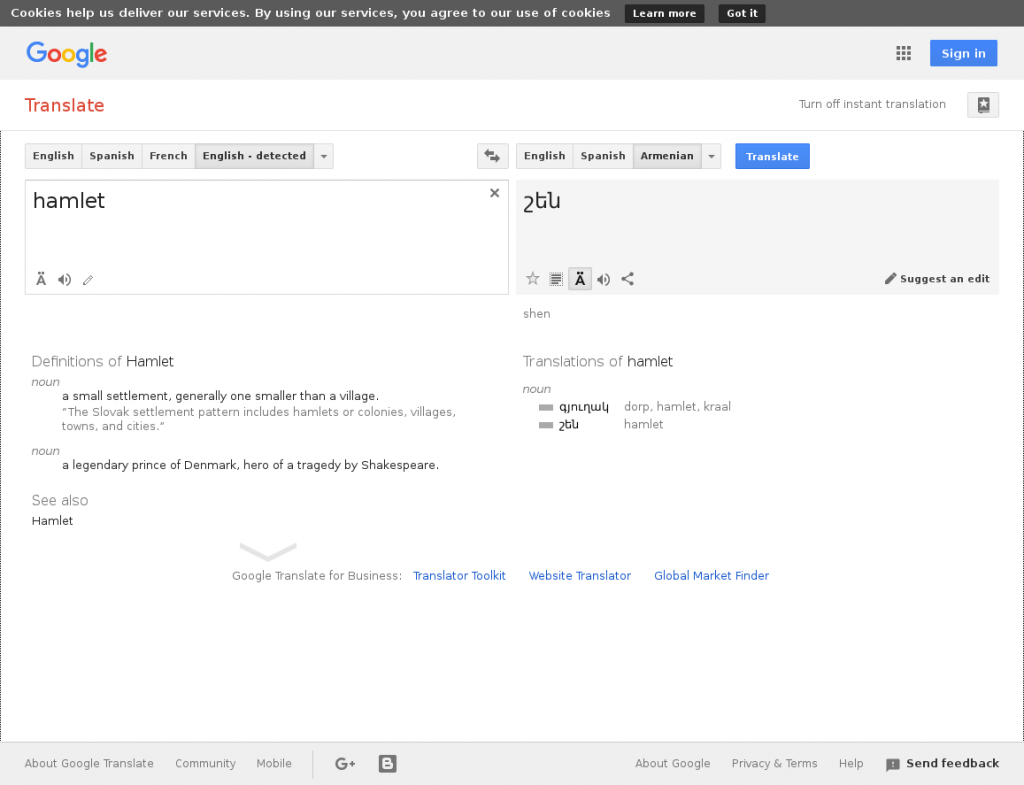
Այդպիսի զուգադիպութիւններ չափազանց շատ էին, երբ գուգլի արդիւնքների բառերի քանակն ու իրենք բառերը լրիւ նոյնն էին, ինչպէս «արմդիկտօ»֊ում։ (:
ու տենց։
այսօր թուանշային գրադարանը ամերիկեան համալսարանի մանուկեան դահլիճում ներկայացրել է իր նոր կայքն ու դիւրակիր ծրագրերը։
կայքը, պարզւում է, ունի նաեւ բառարան։ ընտրեցի պատահական մի բառ, ու փնտրեցի՝

Ժողովուրդ՝
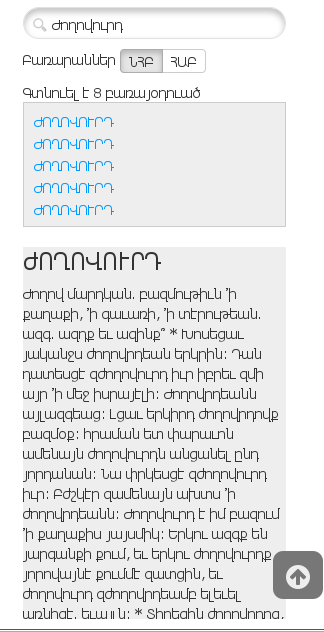
Յետոյ նայեցի ինչպէս է այս բառը երեւում այն բառարանում, որ ես կարողացել էի քաշել enacademic֊ի կայքից եւ կազմել ազատ ֆորմատի բառարան այս յատուկ այդ համար գրուած ծրագրի օգնութեամբ։ Ահա, այսպէս է երեւում Սեյլֆիշ ՕՀ֊ի «Սիդուդիկտ» ծրագրով՝

Մի հատ էլ բառ, թուանշային գրադարանի բառարան՝

իմ պատրաստած բառարանը՝

Թւում է թէ թուանշային գրադարանը օգտուել է իմ աշխատանքի արդիւնքներից։ եւ դրանք գոնէ ինչ֊որ մէկին պէտք եկան, եւ հասանելի կը լինեն մարդկանց իրենց կայքի միջոցով։ (:
կամ էլ մենք օգտուել ենք նոյն աղբիւրից։ այդ դէպքում, տեսնես իրենք ինչպէ՞ս են վերցրել տուեալները, ու ո՞րն է իրենց աղբիւրը՝ էնակադեմիկի բառարա՞նը, թէ՞ այլ աղբիւր է։
հ․ գ․ եթէ իրենց կայքից անկախ բառարանից օգտուելու ցանկութիւն կայ, ապա ահա «ստարդիկտ»֊ի ֆորմատով պատրաստի նիշքերը։
մինչ։
նախորդ գրառման հետքերով, բացառուած չէ, որ գուգլն էլ է օգտուել իմ կոտրած եւ հասանելի դարձրած, ժամանակին «տրոյ»֊ի կազմած «արմդիկտօ» բառարանից՝
Փնտրում ենք «Սիդուդիկտ»֊ում բառը՝


Իսկ ահա գուգլ թարգմանչի արդիւնքները(սեյլֆիշի «թաօ տրանսլատոր» ծրագրով)՝

եւ գուգլի կայքի միջերեսով՝

Այդպիսի զուգադիպութիւններ չափազանց շատ էին, երբ գուգլի արդիւնքների բառերի քանակն ու իրենք բառերը լրիւ նոյնն էին, ինչպէս «արմդիկտօ»֊ում։ (:
#բառարան #էկրանահան #հայերէն
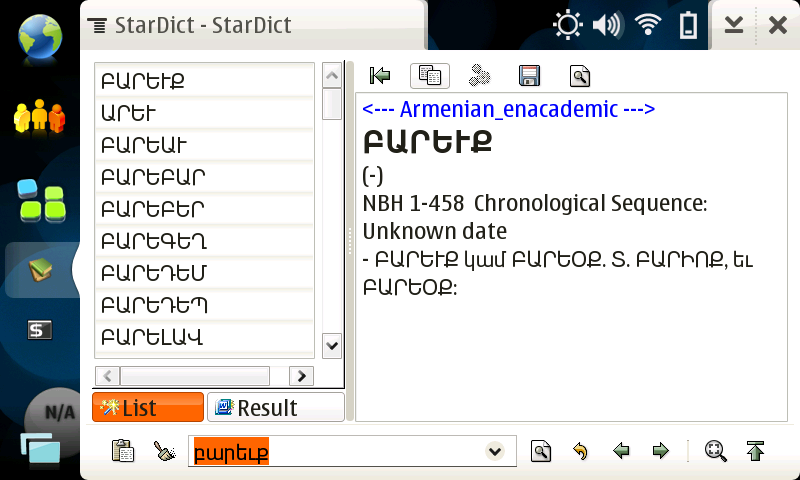
այսօր թուանշային գրադարանը ամերիկեան համալսարանի մանուկեան դահլիճում ներկայացրել է իր նոր կայքն ու դիւրակիր ծրագրերը։ կայքը, պարզւում է, ունի նաեւ բառարան։ ընտրեցի պատահական մի բառ, ու փնտրեցի՝

Ժողովուրդ՝

Յետոյ նայեցի ինչպէս է այս բառը երեւում այն բառարանում, որ ես կարողացել էի քաշել enacademic֊ի կայքից եւ կազմել ազատ ֆորմատի բառարան այս յատուկ այդ համար գրուած ծրագրի օգնութեամբ։
Ահա, այսպէս է երեւում Սեյլֆիշ ՕՀ֊ի «Սիդուդիկտ» ծրագրով՝

Մի հատ էլ բառ, թուանշային գրադարանի բառարան՝

իմ պատրաստած բառարանը՝

Թւում է թէ թուանշային գրադարանը օգտուել է իմ աշխատանքի արդիւնքներից։ եւ դրանք գոնէ ինչ֊որ մէկին պէտք եկան, եւ հասանելի կը լինեն մարդկանց իրենց կայքի միջոցով։ (:
կամ էլ մենք օգտուել ենք նոյն աղբիւրից։ այդ դէպքում, տեսնես իրենք ինչպէ՞ս են վերցրել տուեալները, ու ո՞րն է իրենց աղբիւրը՝ էնակադեմիկից բառարա՞նը, թէ՞ այլ աղբիւր է։ հ․ գ․ եթէ իրենց կայքից անկախ բառարանից օգտուելու ցանկութիւն կայ, ապա ահա «ստարդիկտ»֊ի ֆորմատով պատրաստի նիշքերը։
մինչ։
#բառարան #գրադարան #էկրանահան #թուանշային_գրադարան #հայերէն #Յոլլա #սեյլֆիշ

փաստօրէն, ժխոր բառը վեց երրորդ դարից կայ։
#հայերէն #բառարան #բառ
#էկրանահան #հայերէն #բառարան #բառեր
https://hy.wikipedia.org/wiki/Մասնակից:Chaojoker/Եզրեր/Ֆիզիկա
#հայերէն #ֆիզիկա #եզրեր #բառեր #բառարան #եզրաբանութիւն
ահա բառարաններ սարքող նոր սկրիպտ՝ https://github.com/norayr/reading.ge_to_stardict #բառարան #հայերէն #վրացերէն #ադրբեջաներէն #ազատութիւն
այս բառարանը կարծես միայն արխիւում է մնացել։ այն էլ չեմ կարողանում քաշել։
#բառարան #հայերէն
եւս մի բառարան հասանելի է անցանց։ պարունակում է 53521 բառ։
կարող է հետաքրքրել սա նաեւ։
#էկրանահան #բառարան #հայերէն


եւս մի բառարան հասանելի է անցանց։ պարունակում է 53521 բառ։
կարող է հետաքրքրել սա նաեւ։
#էկրանահան #բառարան #հայերէն
հայերէնի բառարան http://armenian.enacademic.com/
ուզում է իրեն սարքեն ազատ ֆորմատի։
#հայերէն #բառարան #յղում
Իսկական հաքը՝ ինչ֊որ անկապ ու անպէտք բան կոտրելը չէ։ Իսկական հաքը իմաստ պիտի ունենայ, խնդիր լուծի։
Հիմա պատմեմ ինչպէս եմ ես լուծել մի խնդիր։
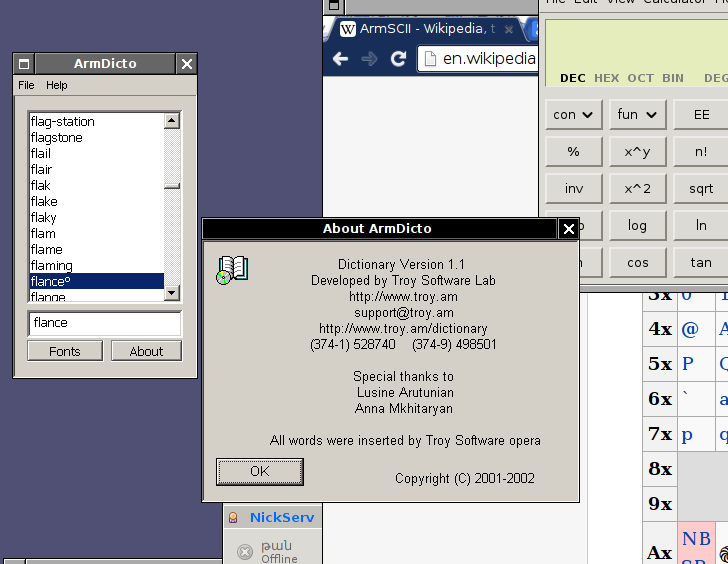
Ժամանակին, 2000֊2001 թուերին կար հաւէս բառարան, որ բոլորը իրենց պարտքն էին համարում իրենց համակարգերում ունենալ, կոչւում էր՝ armdicto։ Պատրաստել էր ոմն Տրոյը, իսկ նրան օգնել էին երկու աղջիկ, ում անունները «էբաութ» բաժնում նշել էր։
Այդ բառարանը անցեալ դարի բառարան է։
Նախ, որովհետեւ այսօր արդեն ընդունուած չէ ազատ ԾԱ֊ի տարածման շնորհիւ (բարեբախտաբար) որ բառարանի հետ աշխատող ծրագիրը, եւ բառարանի նիշքերը իրենք, կապուած լինեն։
Նաեւ, այս բառարանը աշխատում էր Windows ՕՀ֊ում x86֊ի վրայ։
Իսկ ի՞նչ անել GNU/Linux կամ MacOSX օգտագործողների՞ն։
Օկեյ, սա դեռ լուծելի է։ wine֊ի օգնութեամբ լինում է աշխատեցնել որոշ windows ԾԱ GNU/Linux եւ MacOS X համակարգերում։
Ահա եւ աղջիկների անունները՝
Իսկ ի՞նչ եթէ ես ուզում եմ այլ բառարանի ծրագրի հետ աշխատեցնել այս բառարանի բառերի բազա՞ն։
Իսկ ի՞նչ եթէ ես չեմ վստահում ոչ ազատ ԾԱ֊՞ին։ Ի դէպ, Տրոյ անունը լաւ յոյսեր չի ներշնչում։ Ի՞նչ իմանաս ինչ է անում այս ծրագիրը։
Իսկ ի՞նչ, եթէ ես ուզում եմ պատճենել փակցնել թարգմանուած բառը, իսկ այն, փաստօրէն, armscii-8 կոդաւորումով է։
Բայց լաւ, մենք արդեն իրօք 21֊երորդ դարում ենք, եւ ոչ միայն Յունիկոդ ենք օգտագործում,այլ եւ ոչ միայն Ինթել պրոցեսորներ։ Ասենք ես երեւի աւելի շատ ARM ունեմ քան Intel։
Բացի դրանից ես ունեմ PowerPC պրոցեսորով երկու համակարգիչ, իսկ ոմանք ունեն MIPS պրոցեսորներով լափթոփներ։
Իսկ ի՞նչ, եթէ ես ուզում եմ օգտուել այս աշխատանքով իմ խելախօսի վրայ։
Ասենք դուք կարող է ունէք Անդրոիդ կամ ԻՕՍ, իսկ ես ասենք ունեմ Սեյլֆիշ։
Այսինքն մեզ պէտք է այս բառարանը ARM֊ի վրայ։ Ի՞նչ անել։
Նախ կարողանալ հանել այդ բառարանը ծրագրից։
Ես գտել եմ (գուգլի օգնութեամբ) այս ծրագիրը համացանցում՝ http://users.freenet.am/~osprog1/ArmDicto%20v1.1.rar
Չգիտեմ ով է այս osprog1֊ը, բայց շնորհակալութիւն նրան։
Քաշեցինք՝
Հիմա բացենք ռառ֊ով։
Օկեյ, ոչ մի բառարանի նիշք էլ չկայ։
Այն ինչ֊որ տեղ թաքցուած է։ Ո՞րտեղ։ Այստեղ՝ data1.cab նիշքում։
Այո, այսպիսի հաւէս ծրագրեր կան ԻնսթալՇիլդ ցաբ նիշքեր բացելու համար։
Հիմա գտնում ենք main.dat նիշքը Program_Executable_Files/Data պանակում։
Օկ, եթէ փորձենք հասկանալ ի՞նչ ֆորմատի է, բան պարզ չէ։
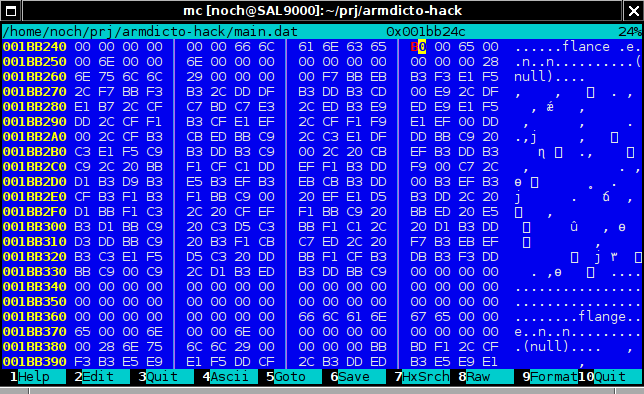
Օկեյ, նայենք այն հեքս խմբագրիչով։
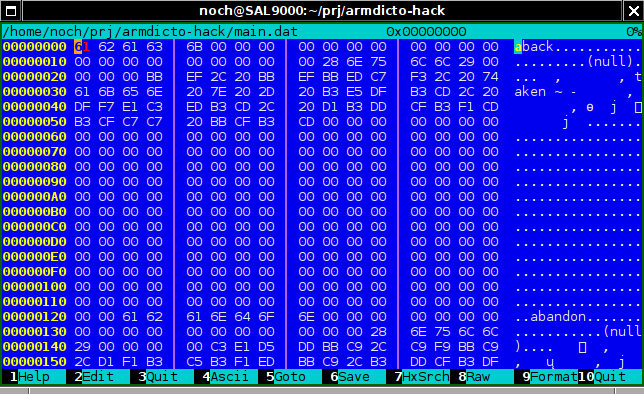
Ահա, տեսնում ենք, ինչ֊որ զրօներ են, յետոյ ինչ֊որ “(null)” յետոյ՝ BB EF 2C 20 BBEF BB ED C7 F3 …
Սա հաստատ ARMSCII-8 է։ Ստուգում ենք՝ այո, թարգմանութեան տեքստն է։
Յետոյ էլի գնում են զրօներ, իսկ յետոյ յաջորդ բառը՝ abandon, եւ ամէնը կրկնւում է։
Լաւ, իսկ ի՞նչ է մեզ պէտք վերջում։ Մեզ պէտք է ասենք tab separated նիշք, ուր սկզբից բառն է, յետոյ ԹԱԲ է գնում, յետոյ բառի թարգմանութիւնը։ Կարծես կարելի է փորձել կոտրել։
Դէ, ամէն ինչ այդքան պարզ չէր։
Նախ, զրօներ անկապ յայտնւում են, պարզւում է, եւ բառերի, եւ թարգմանութիւնների արանքում։
Բաւական ջանք է պահանջում, ահա այսպէս է արւում՝ [https://github.com/norayr/armdicto-hack/blob/master/armdictohack.Mod
]4
Արանքում պէտք է քոնուերտել արմսքի֊ից դէպի յունիկոդ՝ https://github.com/norayr/armdicto-hack/blob/master/ArmsciiUTF.Mod
լաւ, կարծես լինում է։ Սա իրականում ամենաբարդ մասերից էր, չնայած այնքան պարզ անցանք այստեղ։
բայց եւ կոդը ամէն ինչ բացատրում է։
Ինչ֊որ սխալ armscii-8 շարուածք են օգտագործել, այդ պատճառով և֊ը սխալ է, a2֊ի տեղը a8 է, սխալ տառատեսակներ էլ կային, յիշում եմ։ Նախ սա ուղղում ենք՝
Հիմա կարծես թէ նորմալ ելքային նիշք է տալիս, բայց ինչ֊որ անկապ նիշեր կան, ասենք minor բառը նորմալ չի երեւում։
Օկ, նայում ենք մութքային նիշքը։
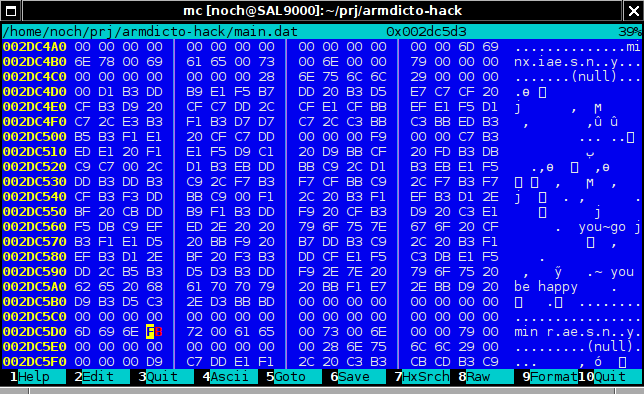
Էս ի՞նչ «FB» է, ինչո՞ւ ոչ նորմալ, լատինատար «o»։ Պարզւում է, fb֊ն armscii֊ի «օ»֊ն է։ Երեւի աղջիկները հաւաքելիս շփոթուել են, կամ սխալ շարուածք ունէին։ Ինչեւէ։ Իսկ ո՞նց է ինքը արմդիկտո֊ն սա ցոյց տալիս։
Պարզւում է՝ ոչ մի ձեւ չի կարողանում։
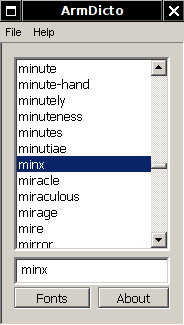
minor բառը պարզապէս չի կարողանում գտնել, ու բաց է թողնում։
Լաւ, մենք գտանք տուեալների բազայի սխալ։ Ուղղենք, եւ հասանելի դարձնենք այս բառը մեր ազատ ծրարգրերում։
Ինչպէ՞ս բայց։ Ես չեմ ուզում ձեռքով նիշք խմբագրել։ Համ էլ, կարող է էլի՞ նման խնդիրներ լինեն։
Աւտոմատացնում ենք։
Ափդեյթ․ հիմա մտածում եմ, ինչքան աւելի էլեգանտ կը լիներ նոյնը անել Օբերոնով՝
Պարզապէս գիշերը չէի մտածել, որ ծրագիրը կարելի է ոչ միայն կոնուերտելու համար օգտագործել։
եւս մի ափդեյթ․ իրականացրի ամէնը Օբերոնով, եւ ուղղեցի եւ֊երը եւ փոխեցի հայերէն տեքստի մէջ հանպիդող սխալ «~» նիշերը ճիշտ «՜» երկարացման նշաններով։ այսպէս, ահա։Ճ
հիմա այսպէս՝
111֊ը 6f֊ն է, այսինքն լատինատառ օ֊ն։
Այո՛, փոխուեց։
Է՞լ ինչ կայ ուղղելու։
Փաստօրէն, այստեղ, gyve բառից յետոյ ինչ֊որ սխալ բառ է՝
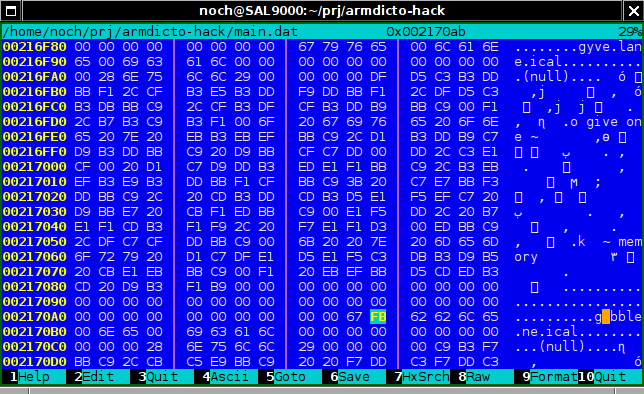
Ահա, եւ կրկին ինքը արմդիկտո֊ն չի կարողանուց ցոյց տալ՝
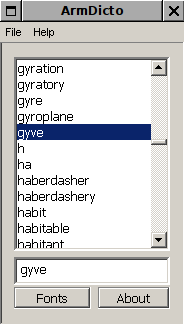
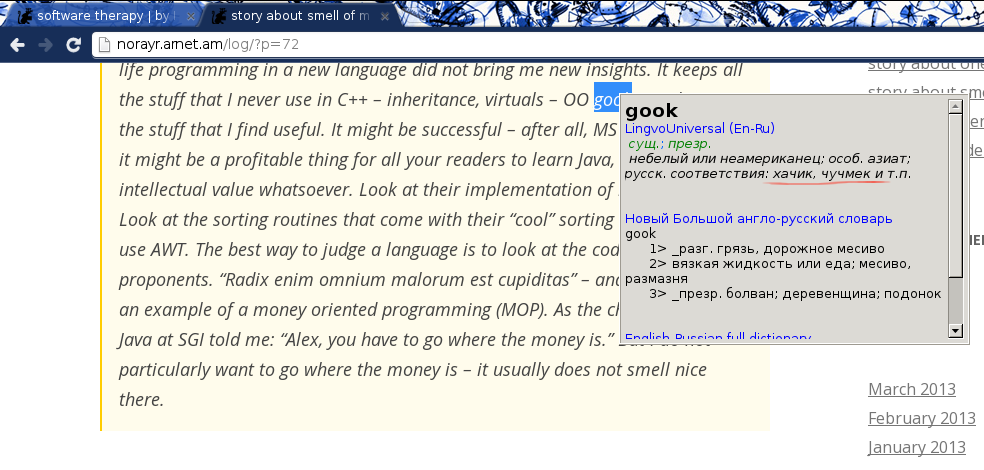
Ի դէպ, ինձ թւում է, ես փորձում էի այս բառը փնտրել, ուզում էի իմանալ, ինչո՞ւ էր իմ սիրած խաղերից մէկը gobbler կոչւում։ Ինչեւէ։
Ֆիքսում ենք՝
Իսկ սա՞ ինչ է, իմ ստացած նիշքում flance֊ից յետոյ ինչ֊որ b0 կայ, ահա եւ մուտքում էլ էր՝
Ի՞նչ է անում, ինչո՞ւ համար՝
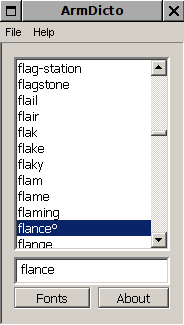
Ֆիքսում ենք՝
Հիմա կրկին աշխատացնում ենք հաքը, ու նայում ինչ է լինում՝
ահա, հիմա եթէ տալիս ենք ասենք ինտերակտիւ stardict_stardict-editor ծրագրին, ասում է որ կրկնւող բառեր կան։ իրօք, դբ֊ի մէջ կան։ եւս մի սխալի տեսակ, որը գտանք։
օկ, սա արդեն հեշտ է լուծւում՝
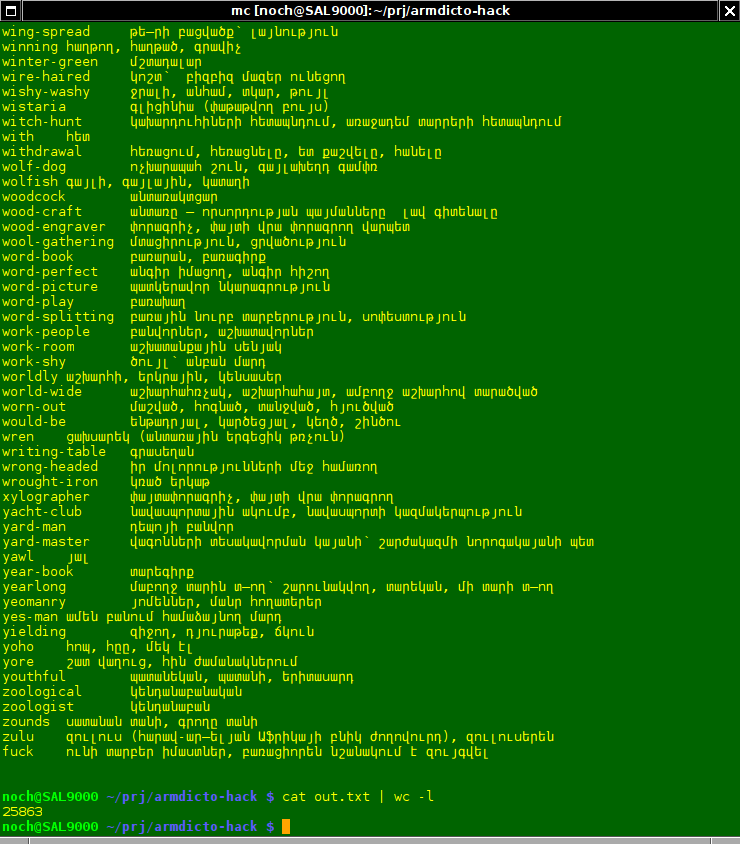
եւ հիմա անելով
ստանում ենք ելքային բառարաններ։
Դրանք կարելի է տեղադրել ~/.stardict/dic պանակի մէջ եւ օգտագործել դեսքթոփի վրայ՝
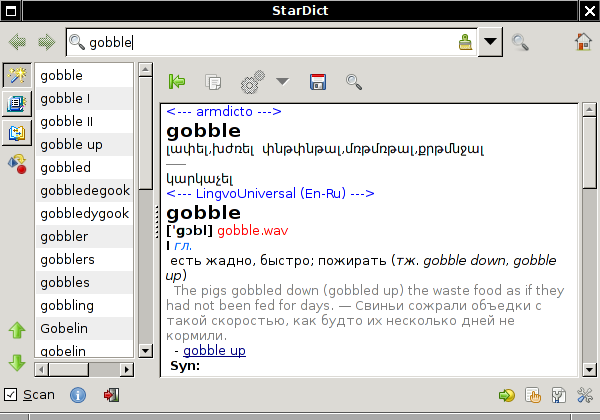
իսկ կարելի է լցնել ~/.local/share/harbour-sidudict պանակի մէջ եւ օգտուել Սեյլֆիշի վրայ՝

Անդրոիդի համար էլ նման բառարաններ կան, դրանք են՝ GoldenDict, ColorDict, Wordmate Fora Dictionary եւ AntTek Dict, կարճ ասած՝ շնից շատ են։
Յոյսով եմ, մարդիկ կան, ով հասկանում են, որ առցանց ծրագրերը, եւ մասնաւորապէս բառարանները, ինչքան էլ լաւը չʼլինեն, մենք չենք վերահսկում, ու դրանք մնում են ՍԱԱՍ, ի տարբերութիւն ծրագրերի ու տուեալների, որ մենք օգտագործում ենք լոկալ։
Ամբողջ նախագիծը՝ հաք անող ծրագրի ելատեքստը եւ սկրիպտը ազատ լցուած են գիթհաբում՝ https://github.com/norayr/armdicto-hack
իսկ բառարանների պանակը՝ այստեղ է http://norayr.am/armdicto/
— http://norayr.am/armdicto/armdicto.zip ստացուած բառարանի նիշքերը
— http://norayr.am/armdicto/armdicto.txt թաբերով բաժանուած բառերի ելատեքստը։
նաեւ հասանելի է գիթհաբում։
ի դէպ, այդ ելատեքստը կարելի է եւ հետ ստանալ բառարանի նիշքերը դեքոմփայլ անելով։
Կրկնում եմ շնորհակալութիւնն անծանօթ Լուսինէ Յարութիւնեանին եւ Աննա Մխիթարեանին, ենթադրում եմ որ իրենք են կազմել այս բառարանը։
բարի գալուստ XXI֊րդ դար, ահա։
ու տենց
ահա, սենց հաբրական գրառում http://norayr.arnet.am/weblog/2014/09/09
#բառարան #հայերէն #հաք #ծրագրաւորում #ուտենց
դեռ այս յղումը թողնեմ, յետոյ մանրամասն կը բացատրեմ ինչ է ։Ճ https://github.com/norayr/armdicto-hack
ահա
#բառարան #հայերէն #հաք #ծրագրաւորում #ուտենց

վիշապն էլ, պարզւում է սանսկրիտի վիշ (թոյն) արմատից է։ Վիշնու֊ն էլ է նոյն արմատից։ Շատ հետաքրքիր յօդուած է այստեղ
Անհեթեթ մեծ օձ, մանաւանդ ջրային, կէտ անասունը։
իսկ վիշապակ֊ը օձի ձագ է։
#վիշապաքաղ #վիշապացեալ #վիշապաշունչ #վիշապազունք #վիշապաձայն #վիշապակ #ვეშაპი #გველეშაპი #բառարան #ծագումնաբանութիւն #վիշապ ###
https://www.youtube.com/watch?v=8HiviV7-It0
#նիկոլ #պարտադիր #բառարան #խորհրդարան
— Ես մի պրոֆեսորի ամառանոցն էի հսկում,— պատասխանեց շունը։— Պրոֆեսորը կենդանիների լեզուն էր ուսումնասիրում։ Այդ ժամանակ էլ հենց սովորեցի։
— Դա երեւի իմ պրոֆեսորն է,— բղավեց կատուն։— Սյոմին Իվան Տրոֆիմովիչը։ Նա կին ուներ, երկու երեխա եւ մեկ տատիկ՝ ավելը ձեռքին։ Ու միշտ զբաղված էր «Ռուս—կատվերեն» բառարան կազմելով։
— «Ռուս—կատվերեն» չգիտեմ, բայց «Որսորդա—շներեն» կազմում էր։ Եվ «Կովա—նախրապաներեն» նույնպես։ Իսկ տատիկի ձեռքին է՛լ ավել չկա։ Նրա համար փոշեծծիչ են գնել։
— Միեւնույն է, դա իմ պրոֆեսորն է,— ասաց կատուն։
— Իսկ նա հիմա որտե՞ղ է,— հարցրեց տղան։
— Աֆրիկա գնաց։ Գործուղման։ Փղերի լեզուն ուսումնասիրելու։ Իսկ ես մնացի տատիկի մոտ։ Միայն թե մենք յոլա չգնացինք։ Ես սիրում եմ, որ մարդ ուրախ բնավորություն է ունենում՝ երշիկահյուրասիրողական։ Իսկ նա, ընդհակառակը, ծանր բնավորություն ուներ։ Ավելա—վռնդողական։
— Ճիշտ է,— հաստատեց կատուն,— բնավորությունն էլ էր ծանր, ավելն էլ։
աղբիւր
#մէջբերում #քաղուածք #զրոյց #գրականութիւն #գրքեր #քեռի֊ֆեոդոր #կատուներ #շներ #ռուսերէն #կատվերէն #շներէն #գիտութիւն #պրոֆեսոր #բառարան #տատիկ #յոլա

փաստօրէն, ստարդիկտը ունի ռեվերս փնտրելու հնարաւորութիւն։ it turned out, stardict has reverse (full text) search feature.
#փաստորեն #բառարան #ստարդիկտ #ռեվերս #որոնում #stardict #dictionary #reverse #search #full-text #feature
#փաստորեն սենց #բառարան էլ կայ՝ http://www.microsoft.com/Language/en-US/Search.aspx
#հայերեն #հայերէն #եզրեր
համակարգչային եզրերի բառարան՝ http://tarumian.am/glossword/1.8/index.php/list/2/1.xhtml
#եզրեր #եզրաբանություն #համակարգիչ #բառարան
ես օգտագործում եմ հեք արած Լինգվո ֊ի բառարանները Ստարդիկտ ֊ով։
Ահա թե ինչ եմ այնտեղ այսօր գտել։ Հիանալի է։
ու տենց
ուրեմն, գործընկերս երբ ազատ ֆորմատի հայերեն բառարան էր պատրաստում, դե պարզ է, սքան է արել սկզբից, հետո ocr հետո սփելչեք։ Ու այդ ֆայնրիդերը ամեն տեղ, ուր հանդիպում էր ՈՒ տառը, հա սխալվում, գրում էր ՈԻ։ այդպես, նա ձեռքով դե ստուգում էր, ու մի հատ էլ անցավ լրիվ ՈԻ տառերով։
Փաստորեն, միայն մեկ բառ կար բառարանում, ուր ՈԻ կապակցությունը հանդիպեց։ Դա ԷԳՈԻՍՏ բառն էր, օտար բառը։
եւ այդպես
http://norayr.arnet.am/weblog/2013/01/20/ասք-էգոիզմի-մասին/ #էգոիզմ #բառարան #հայերեն #փաստորեն
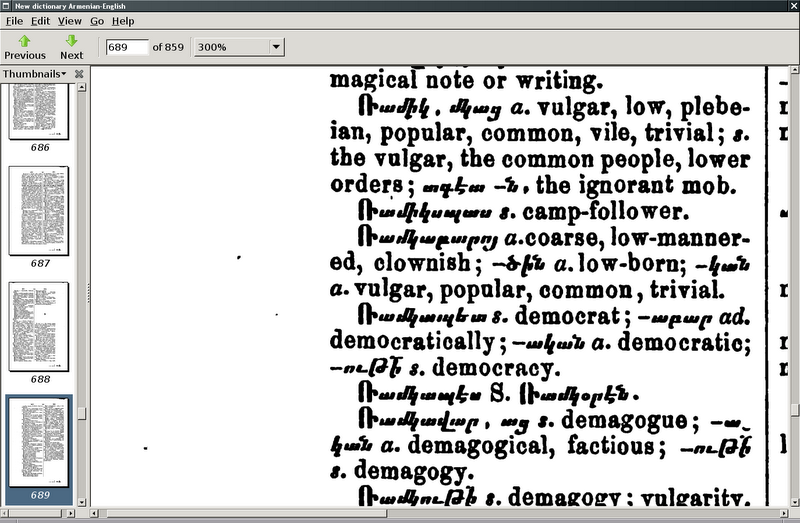
այսինքն, վուլգար === գեղցիավարի
ներեցեք իմ պերլոտ նոտացիայի համար
հիշեցնեմ՝ http://dictionaries.arnet.am
_ու տենց _
Hereby I present an english-georgian dictionary for Stardict
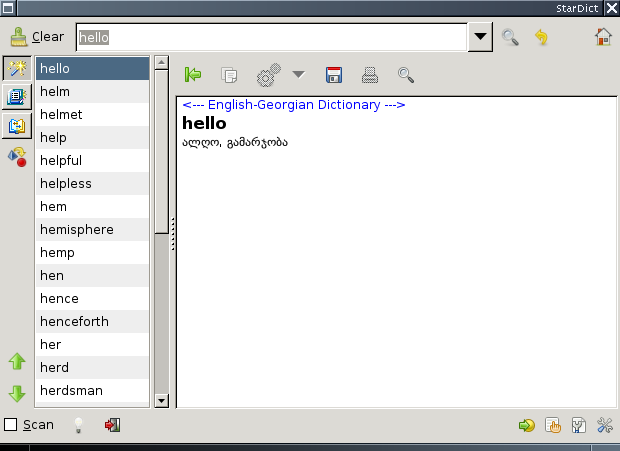
Stardict, is an open-source dictionary software. StarDict runs under Linux, Microsoft Windows, FreeBSD, Internet Tablet OS and Solaris. Dictionaries of the user’s choice are installed separately.
This dictionary contains 8680 words, and generated from the original pdf files found at http://www.georgianweb.com/pdf/lexicon.pdf
We’ve prepared Stardict dictionary, because I didn’t find any other open format georgian electronic dictionary I could use with Stardict.
Download from here
There you can also download english-armenian, and new, 0.4 version of armenian-russian dicts.
და ასე
ու տենց
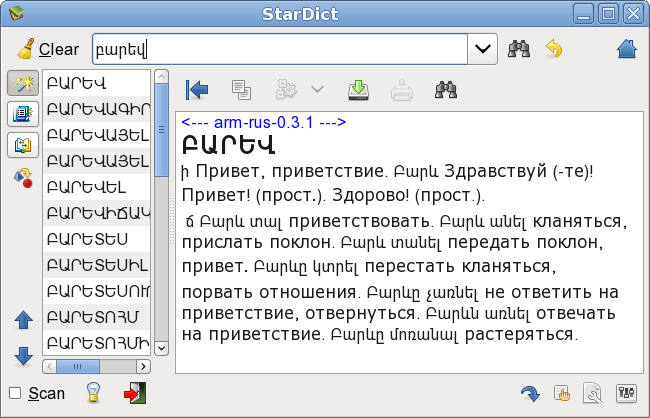
я уже писал, что мой друг сканирует и поправляет ошибки в армяно-русском словаре (70.000 слов). Ранее мы с ним еще один словарик замутили англо-армянский
Так вот, выкладываю часть этого нового словаря – 300 страниц из семьсот друг просмотрел и пофиксил ошибки распознования. Пофиксены только армянские слова, в русском возможны баги.
И самое главное – нужна помощь, если неохота еще год ждать, если человек десять соберется, то оставшиеся 400 страниц можно будет быстренько просмотреть и пофиксить
_ու տենց _
Мой друг распознавал файнридером один армянский словарь, чтобы полку стардиктовских словарей прибыло, и при этом случайно заметил, что файнридер распознает все ՈՒ как Ո и Ի на всякий пожарный, а не как Ո и Ւ(վյուն)
И тогда он решил вручную пройтись по всему тексту и скорректировать где надо в ՈՒ
Оказалось, комбинация букв Ո и Ի в армянском словаре встретилась лишь раз – в слове ԷԳՈԻՍՏ (эгоист) которое понятно иностранное:)
_ու տենց _

ՊՐՈՍՏԻՏՈՒՑԻԱ

հարկադրված պոռնիկություն, վոր դարձել ե արհեստ – պրոֆեսիա։ **Բուրժուական հասարակության մեջ ամեն ինչ առ-և-տուրի առարկա յե դարձել։ Նույնպես և սերը։** Անբավարար աշխատավարձը, աշխատանք ստանալու դժվարությունը ստիպում են բազմաթիվ դժբախտ կանանց ծախելու իրենց մարմինը։ Ինքը բուրժուազիան, վոր ծնել ու սնել ե այդ յերևույթը,
կեղծավորաբար աղաղակ ե բարձրացնում վարի դասակարգերի կանանց անբարոյականության մասին, արհամարանքի սյունին ե զամում նրանց և նրանց իրավունքները սահմանափակում, միաժամանակ սանիտարական հսկողության միջոցեվ աշխատում ե իրեն ապահովել վարակումից։

(տեսե՜ք, սադրիչ բառը չի օգտագործվում)
Պրոստիտուցիան սոցիալական չարիք ե, վորի արմատները գտնվում են բուրժուական հասարակության պայմաններում․ դա կվերացվի այն ժամանակ, յերբ կվոչնչացվի կապիտալիստական աշխարհը։
ԴԵՄՈԿՐԱՏԱԿԱՆ ՀԱՆՐԱՊԵՏՈՒԹՅՈՒՆ

բուրժուական պետական կազմ․ որենսդրական բարձրագույն իշխանությունը արտաքուստ պատկանում ե ամբողջ ժողովրդի ներկայացուցիչներին, բայց փաստորեն իշխում ե բուրժուազիան
ԴԵՄՈԿՐԱՏԻԱ

(ժողովրդավարություն բառը դեռ չէր գործարկվում)
և տեղական հարցերի վճռման խնդրում կիրառում ե տեղական ինքնավարարություն ու ավտոնոմիա։ Դեմոկրատիան իր դասակարգային բովանդակությամբ կարող ե լինել պրոլետարական – այն յերկրներում, ուր քաղաքական իշխանությունը գտնվում ե պրոլետարիատի ձեռքին, և կարող ե լինել բուրժուական – կապիտալիստական իշխանությունը գտնվում ե բուրժուազիայի ձեռքին։ Վերջին դեպքում Դ-ի սահմանած իրավունքներն ու ազատությունները բուրժուազիան սովորաբար ի չիք ե դարձնում՝ հենց վոր բանվոր դասակարգը քայլեր ե անում դրանք լայն ոգտագործելու հոգուտ իր դասակարգային շահերի։ Բոլոր իրավունքներից ամենից առաջ և ամենամեծ չափով ոգտվում ե բուրժուազիան՝ բանվոր դասակարգի դեմ կռվելու և նրա դասակարգային գիտաքցությունը մթագնելու համար։ Բուրժուազիան դասակարգային պայքարի սուր մոմենտներին դեն ե գցում կառավառման դեմոկրատական ձևը, անցնելով բացարձակ բռնության (ֆաշիզմ) մեթոդներին։
Բուրժուական Դեմոկրատիայի փայլուն որինակ են հանդիսանում արդի Անգլիան ու Ֆրանսիան, ուր բուրժուազիան առաջ ե քաշել ձախ և բանվորական կառավարություններ։ Աշխատավոր մասսաների համար դեմոկրատիայի իսկական իրագործումն կլինի միմիայն պրոլետարիատի քաղաքական և տնտեսական տիրապետության պայմաններում։ Դեմոկրատիայի փայլուն անալիզ տվել ե ընկ․ Լենինը իր մի շարք յերկերում։
ՄՈՎՍԵՍ

հրեական ժողովրդի առասպելական առաջնորդը և որենսդիրը, վորն հրեաներին դուրս ե բերել յեգիպտական գերությունից․ նրա կյանոը պճնազարդված ե ֆանտաստիկ առասպելներով՝ հրաշքների մասին, վոր նա իբր թե գործել ե։
ԼՅՈՒՄՊՆ – ՊՐՈԼԵՏՈՐԻԱՏ

մարդկանց այն խավը, վոր չի մասնակցում հասարակական արտադրության մեջ, մատնված ե պարազիտային գոյության․ բոսյակները, մուրացկանները։ Լյումպըն-պրոլետարիատը ատելով ատում ե բուրժուական հասարակությանը, բայց իր ապադասակարգային դրության հետևանքով անընդունակ ե դասակարգային կազմակերպված պայքարի։

ԳԵՐԱՐՏԱԴՐՈՒԹՅՈՒՆ

ապրանքների արտադրությունը այնպիսի չափերով, վոր գերազանցում ե բնակչության գնողական ընդունակությունը։ Կապիտալիզմի բնորոշ հատկանիշը, արտադրության անարխիայի և կապիտալիստների մրցությունների հետևանք, որոնք (կապիտալիստները) ՛շուկա յեն դուրս բերում մեծ քանակությամբ ապրանք՝ հաշվի չարնելով բնակչության գնողական ունակությունները։
Գ․֊յան հետևանքով լինում են արդյունաբերական կրիզիսները, արտադրության մեջ լճացում, գործազրկություն։
(ահա թե որն է համաշխարհային ճգնաժամի պատճառը փաստորեն)
ԱՐՏԱԿԱՐԳ ՀԱՆՁՆԱԺՈՂՈՎ (Չեկա)

հակահեղափոխության, սաբոտաժի, սպեկուկյացիայի և ի պաշտոնե գործած հանցանքների դեմ մաքառելու համար ե։ Ա․ Հ․-ը կազմվեց Հոկտեմբերյան հեղափոխությունից հետո անմիջապես, հերբ բուրժուազիան ձգտելով տապալել Խորհրդային Իշխանությունը, սկսեց դիմել հակահեղափոխական դավադրությունների, ապստամբությունների և այլն։
Ա․ Հ․-ը բաց ե արել հակահեղափոխական շատ դավադրություններ, բանտարկել ե բազմաթիվ վնասարար սաբոտաժնիկների, սպեկուլյանտների, բանդիտների և դավադիրների, լրտեսների և բանվորա-գյուղացիական իշխանության այլ չարանենգ թշնամիների։ Ամեն մի նահանգ ունի իր առանձին Ա․ Հ․-ը։ Բուրժուազիայի և ազնվականության դիմադրությունը վերջնականապես ճնշելու համար, Խորհրդային Կարավարությունը հարկադրվեց դիմելու կարմիր տեռորի, որի գործիքը դարձավ Ա․ Հ․-ը (և նրա որգանները տեղերում)։ Արտաքին ֆրոնտներում և երկրի ներսում հակահեղափոխությունը վերջնականապես ճնշելուց հետո, Ա․ Հ-ը վերածվեց (1922 թ․) Պետական Քաղաքական Վարչության (Г. П. У – Գեպեու ), իր ֆունկցիաները բավական կրճատելով։

ԴԱՇՆԱԿՑՈՒԹՅՈՒՆԸ, ՅԵՎ ԴԱՇՆԱԿՑԱԿԱՆ ԿԱՌԱՎԱՐՈՒԹՅՈՒՆԸ․

Հ․ Հ․ Դաշնակցական կուսակցությունը ազգային ****** բուրժուական կուսակցություն ե, բաղկացած գլխավորապես ինտելիգենտներից։ Յերկար տարիների ընթացքում «ծովից-ծով Հայաստանի» յերազանքներով ապրելով, նա իր անմիտ քաղաքականությամբ կոտորել տվեց Տաճկստանի հայությունը, իսկ Կովկասում – հրահրեց ազգային կրքերը և նպաստեց հայ-թուրքական ջարդերին**։ Յերբ Հոկտեմբերյան հեղափոխությունից հետո Անդրկովկասը ՌՊՍՖՀ-ից անջատվեց, ազգային կուսակցությունների (մենշեվիկների, դաշնակցականներ, երերների և մուսավաթիստների) գլխավորությամբ հիմնվեց Անդրկովկասյան Հանրապետությունը, իսկ հետագայում, կարճ միջոցից հետ (երբ չռուս զինվորները տարերային կերպով ձգեցին տաճկական ֆրոնտը) Անդրկովկասը բաժան-բաժան յեղավ, դաշնակցականներն ևս (Վրաստանի և Ադրբեջանի որինակով) կազմեցին Հայաստանի առանձին հանրապետություն։ Անցնելով յերկրի կառավարության գլուխ՝ Դաշնակցությունը իր անմիտ քաղաքականությամբ ավերի ու սպանությունների վայրը դարձրեց։ Պատերազմեց Վրաստանի դեմ, պատերազմեց Ադրբեջանի դեմ, պատերազմեց Տաճկաստանի դեմ։ Արտաքին թշնամիների վտանգից զատ, յերկրի ներսում իր իս ձեռքով ( մաուզերիստ խմբապետների) կատարած ալան-թալանը, սպանությունները, կատարյալ անիշխանությունը յերկիրը դարձրին սովի, հրի ու սրի վայր, ուր տասնյակ հազարավոր գաղթականներ ոի վորբեր փողոցներում կոխկռտվելով նվվում եյին ու քաղցից և համաճարակից մեռնում։ Անվերջ սայլերով եյին կրում դրանց դիակները և հսկայական փոսերով կիսաթաղ անում․․․ Այդ դրությունը յերկար տևել չեր կարող, և Հայաստանի աշխատավորությունը վոտքի յելավ, դաշնակներին յերկրից խռկեց ու առաջ բերավ Նոյեմբերյան (1920 թ․) հեղաշրջումը։ Դաշնակցության իշխանության հաստատումը **Հայաստանում Հոկտեմբերյան հեղափոխության դեմ ուղղված մի ակտ եր **և տեղի ունեցավ հակառակ բանվորի ու գյուղացու ցանկության․ առանց ժողովրդական լայն մասաների գիտության․․․
ու տենց մի քանի էջ․․․
ԻՆՏԵԼԻԳԵՆՑԻԱ

կրթված դասը մանր և միջակ բուրժուազիայի․ ազատ պրոֆեսիաների ներկայացուցիչները, արվեստների սպասավորները, արդյունաբերական ձեռնարկների կազմակերպողներն ու ղեկավարները՝ ինժեներները։ Կապիտալի մոտ ծառայության մեջ գտնվելով, նրանք կապիտալիստական հասարակության մեջ հանդիսանում են մեծ մասամբ բուրժուական իդեոլոգիայի մարմնացումն և բուրժուազյայի լիբերալ մասի քաղաքական տրամադրությունների ու ձգտումների արտահայտիչներ։
Մեր խնդիրն ե



եւ այդպես
Мне очень нравится словарик Стардикт. Он отркытый, переносимый, легкий, для него есть очень много словарей
Он позволяет читая текст, выделять незнакомые слова, и показывает всплывающие переводы.
Один мой коллега сконвертировал словарь, который используется с лингво, в формат стардикта, но он содержит всего 7700 слов.
Раньше был такой проект: dictionary.am или troy.am что вообщем одно и тоже. Там был онлайн словарь, а также словарик для виндовс.
Этот словарик ничего себе работал под вайн, и даже отображал армскии символы, подгружая фонты из своей папки.
Там было примерно 18000 слов.
Оба сайта давно закрылись, словать больше скачать нельзя…
Как-то раз подумалось, что неплохо бы сконвертировать его базу в стардиктовский, открытый формат. Сели мы с коллегой, открыли ее в hex editor-е и через некоторое время поняли, что к чему.
Программа на Обероне ее сконвертировала закодированную базу в текстовый файл, который я передал коллеге, а он сгенерировал стардиктовский словарик. Конечно, на этот раз в юникоде.
Стардикт существует почти для всех мыслимых платформ а скачать его можно здесь
А вот и сам словарик в формате стардикта.
Под unix его нужно лишь распаковать в папку dic, которая в /usr/share/stardict обычно, или в его префиксе 🙂
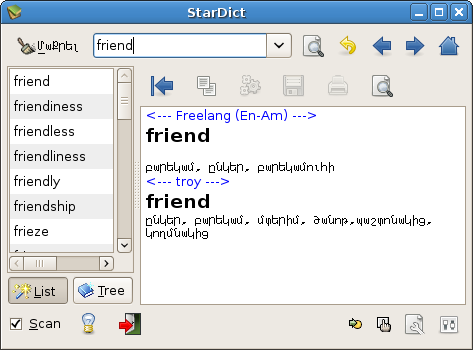
Уже почти год прошел, сайт не появился, и я подумал, что наверное авторы против не будут, если словарик не пропадет, а им пользоваться будут…
Кто ни-будь кроме меня пользуется этим словарем?
